name: centering layout: true class: center, middle --- name: coverpage # 今、時系列DBが熱い(熱いとは言っていない?) Masayoshi Nomura / @nmrmsys 2018/04/21 第8回 関西DB勉強会 --- layout: false ## 自己紹介 .introduce-left[ ### ■ なまえ: 野村 昌由 ### ■ 業務システム開発</br> とインフラ業 ### ■ 今度こそ開発に戻れるかも!?</br> シェル芸は実用主義派、Docker</br> Rancher、PostgreSQL移行中、</br> 時系列DB、データ分析、IoT等 ] .introduce-right[ .center[ [](https://nmrmsys.github.io/) ### @nmrmsys ] ] ??? 本名のローマ字綴りを子音だけにしたもの、アバターは Tim O'Reillyさん Web2.0</br> この資料の大体の画像には元情報への参照リンクが張ってあるので公開後に見てね</br> --- ## 時系列(Time Series)DBとは ```xml name: census ————————————— time location scientist butterflies honeybees 2015-08-18T00:00:00Z 1 langstroth 12 23 2015-08-18T00:00:00Z 1 perpetua 1 30 2015-08-18T00:06:00Z 1 langstroth 11 28 2015-08-18T00:06:00Z 1 perpetua 3 28 2015-08-18T00:07:00Z 1 langstroth 10 20 2015-08-18T00:07:00Z 1 perpetua 2 25 2015-08-18T00:08:00Z 1 langstroth 8 18 2015-08-18T00:08:00Z 1 perpetua 5 22 2015-08-18T05:54:00Z 2 langstroth 2 11 2015-08-18T06:00:00Z 2 langstroth 1 10 2015-08-18T06:06:00Z 2 perpetua 8 23 2015-08-18T06:12:00Z 2 perpetua 7 22 2015-08-18T06:18:00Z 2 langstroth 3 10 2015-08-18T06:24:00Z 2 langstroth 4 9 2015-08-18T06:30:00Z 2 perpetua 9 22 2015-08-18T06:36:00Z 2 perpetua 8 21 ``` ## プライマリキーがタイムスタンプ ??? 今日は学生さんが多数お越しで、わかり易くとのオーダーが出てますので、もうちょっと説明しますと</br> 蝶と蜜蜂の個体数調査、場所と学者が二か所二人</br> プライマリキーというのは、日本語で主キーですから、各データ行が日時で記録識別されるDBというものです。</br> --- ## RDBじゃダメなんですか? [](https://ja.wikipedia.org/wiki/B%2B%E6%9C%A8) ## 一般的なB+treeでは大量の挿入で限界 ??? Btreeインデックス、索引はキー値を二分探索で見つけ出す為の情報</br> レコード数が多くなればなるほど、ディスクへのランダムアクセスが多くなるのが原因</br> --- ## NoSQL(KVS)では[LSM-Tree](http://tattsun.hateblo.jp/entry/2016/02/13/163207)なるものが [](https://www.slideshare.net/DmitriBabaev1/cassnadra-vs-hbase/4) ## シーケンシャルに書き込みが出来て高速 ??? NoSQLてのは SQL/RDBとは違うんですよ!といいたいバズワード</br> キーバリューストアはメモリ上にキーと値を置いて探せば早いやんMemTableのとこ</br> SSTableのSSはSortedStringの略で定期的なコンパクション処理でマージソートしてまとめられる</br> --- ## InfluxDBはそれをさらに改良して </br> [](https://yakst.com/ja/posts/3327) </br> ## より時系列DBに最適化したのを実装 ??? 列指向カラムナーDB、列数が増えてもパフォーマンス影響が少ない、データ圧縮が掛かり易い</br> 時系列の連続データの圧縮方法はいろいろあるが、正直よくわからんので割愛</br> --- ## おかげさまで業界シェア3年連続No1! [](https://db-engines.com/en/ranking/time+series+dbms) ??? 横のグラフの青い線がInfluxDB</br> RRDtoolとかGraphiteとかPrometheusとかサーバ監視ツール由来のものが多い印象</br> Multi-modelのeXtremeDBとか私がもう一つ気になってるTimescaleDBってのもあって</br> --- ## PostgreSQL拡張で実現したのもあるけど </br> </br> [](https://docs.timescale.com/v0.9/introduction/architecture) </br> </br> ## 欲しい機能は他にもいろいろあるんじゃ ??? Chunkと呼ばれる時系列の断片を繋ぎ合わせて一つのHypertableとして扱えるようにしている</br> TimescaleDBは時系列データテーブルじゃないテーブルも同じDBで使えてジョインなども出来るのが売り</br> ならば InfluxDBは?という事になるのですが</br> --- ## その辺は去年末のアドカレに書いたので </br> [](https://qiita.com/nmrmsys/items/cdeb4afa76c591acfd3f) </br> ## 詳細はQiitaで!ではあんまり過ぎるので ??? この NoSQL & NewSQL Advent Calendarは他にも変わったDBが色々紹介されてて面白い --- ## 重要なポイントだけ順に上げていくと ## 時間範囲を考慮した集計 ```sql -- SELECT -- <function>(<field_key>) -- FROM_clause -- WHERE <time_range> -- GROUP BY time(<time_interval>,<offset_interval>),[tag_key] -- [fill(<fill_option: null/numeric/linear/none/previous>)] SELECT MAX(water_level) FROM h2o_feet WHERE time >= '2015-09-18T16:00:00Z' AND time <= '2015-09-18T16:42:00Z' GROUP BY time(12m,3m),location fill(0) ``` ## 集計する時間間隔、開始オフセット、</br>時間間隔内にデータが存在しなかった</br>場合に何をセットするか ??? ヌル、数値指定、線形補完、ポイント無し、前データ値 --- ## 分析に役立つ組込み関数群 ### 集計関数は COUNT(), DISTINCT(), SUM() の他に</br> INTEGRAL(), MEAN(), MEDIAN(), MODE(),</br> SPREAD(), STDDEV() ### 選択関数は MIN(), MAX() の他に</br> FIRST(), LAST(), TOP(), BOTTOM(),</br> PERCENTILE(), SAMPLE() ### 変換関数として CUMULATIVE_SUM(), DERIVATIVE(),</br> DIFFERENCE(), ELAPSED(), MOVING_AVERAGE(),</br> NON_NEGATIVE_DERIVATIVE(),</br> NON_NEGATIVE_DIFFERENCE() ### 予測関数として HOLT_WINTERS() ??? 積分、平均、中央、最頻、差分、標準偏差</br> 最古、最新、上位、下位、百分位、サンプリング</br> 累積和、導関数、差分、経過時間、移動平均、非負導関数、非負差分</br> ホルト・ウィンタース法、過去データを元にトレンドや季節のパターンから予測</br> --- ## データ期限廃棄とダウンサンプリング ```sql -- 2時間のRPを作成、デフォルトに設定 CREATE RETENTION POLICY two_hours ON food_data DURATION 2h REPLICATION 1 DEFAULT -- 52週のRPを作成 CREATE RETENTION POLICY a_year ON food_data DURATION 52w REPLICATION 1 -- 30分間隔でダウンサンプルしたデータを52週のRPのデータとして追加するCQ -- 実行間隔はGROUP BY time()の間隔が自動で設定される、新データの集計が必要なタイミング CREATE CONTINUOUS QUERY cq_30m ON food_data BEGIN SELECT mean(website) AS mean_website, mean(phone) AS mean_phone INTO a_year.downsampled_orders FROM orders GROUP BY time(30m) END ``` ## 直近2時間だけ 1分間隔の詳細なデータを保持し、それ以降は30分間隔の平均値 --- ## ここまでは他製品でも大体サポート ## わりと大きな特徴としてスキーマレス ```sql weather,location=us-midwest temperature=82 1465839830100400200 | -------------------- -------------- | | | | | | | | | +-----------+--------+-+---------+-+---------+ |measurement|,tag_set| |field_set| |timestamp| +-----------+--------+-+---------+-+---------+ INSERT weather,location=us-midwest temperature=50 SELECT * INTO weather_copy FROM weather ``` ## かなりSQLに似せた InfluxQLが入り易い ??? HTTP APIからは上記のLINEプロトコル形式のレコードをバルクで受け取れる</br> フィールド定義を行わず、後からのデータ追加で自由に項目追加が可能、必須項目の指定も無い</br> --- ## TICK Stackというのが構築されてて [](https://www.influxdata.com/time-series-platform/) ??? この辺のネーミングセンスがかなり好きで、時系列データプラットフォームで tick-stackとか</br> InfluxDBの Influxは流入って意味、Kapacitorも後で説明しますが言い得て妙だなと</br> 全てのコンポーネントがGoで作られていて、開発コミュニティも活発で今時っぽいなーと</br> --- ## Telegraf 多機能簡単設置のエージェント [](https://github.com/influxdata/telegraf) ## execとか汎用的に使えるプラグインも ??? GO製の単一バイナリに設定ファイルで監視したいサービスのプラグインを有効化する方式</br> 書いたプラグインはビルドに取り込まれないと使えないのでコントリビューションが活発化する仕組み</br> --- ## Chronograf 初期設定不要の可視化 [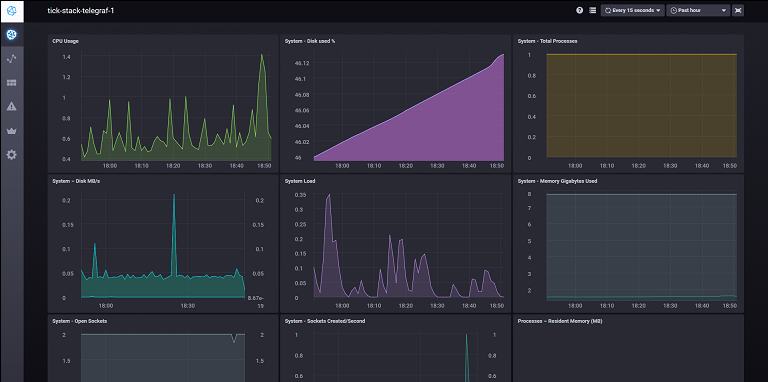](https://docs.influxdata.com/chronograf/v1.3/) ## TICK Stackの基本の設定はここから可能 ??? 特に何も設定しなくとも Telegrafでデータが送られて来ているホスト一覧と主要な監視項目のグラフは見れる</br> データエクスプローラーでカスタムクエリのプレビュー実行、満足したらカスタムダッシュボードを作成</br> 特定の閾値を超えたらアラート通知する設定や、一定期間ごとにデータ処理をおこなうバッチ設定</br> DB管理やユーザ管理</br> --- ## Kapacitor 時系列データコンデンサ [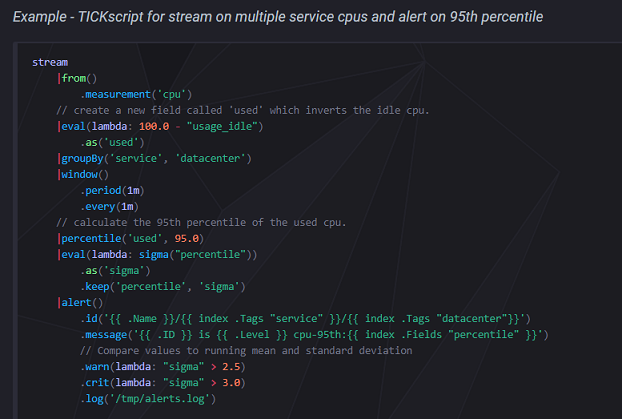](https://docs.influxdata.com/kapacitor/v1.3/introduction/getting_started/#a-real-world-example) ## 時系列ストリームを溜めたり放出したり ??? コンデンサー、スペルをもじってある、CQに似た機能だがさらに高機能</br> 閾値を超えたらアラート通知したり、データを集計加工して別テーブルに保存等</br> TICKscript、メソッドチェインとデータパイプライン記述、streamとbatch</br> sigmaは標準偏差を求める、どれぐらい大きくグラフが動いたか?</br> --- ## 公式のTICK-dockerが放置されてる? [](https://github.com/nmrmsys/rancher-catalog/tree/master/templates/tick-stack/4) ??? Dockerイメージはリリースごとに更新されてるので、後は各自でって事なのか</br> 何にせよ不便なので docker-composeコマンド一発でサクっと起動するテンプレート</br> いろいろ変更を試してみる時に楽な様に設定ファイルを一つのコンテナにまとめてある</br> --- ## InfluxDataの製品ページが激アツなので </br> [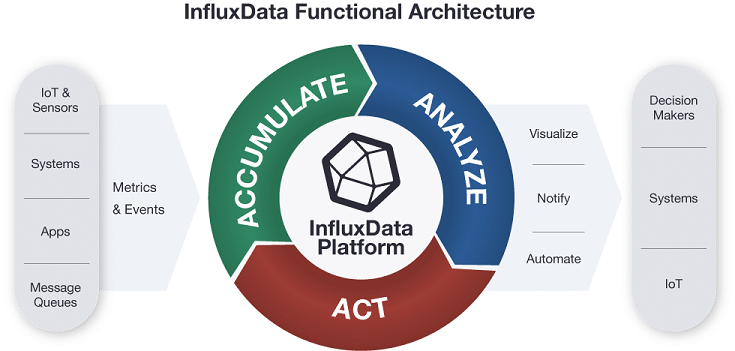](https://www.influxdata.com/products/) </br> ## ぜひ読んでみることをオススメします。 ??? 蓄積</br> Telegrafで大抵のデバイス・サーバ・サービスからInfluxDBにインテグレーション可能</br> 分析</br> InfluxDBの時系列データに最適化された問い合わせ、Chronografでの素早いデータの可視化・随時探索</br> 行動</br> Kapacitorによるリアルタイムストリーミングカスタムデータ処理、それにトリガーにしたアクションの実行</br> --- ## 要約すると - ### スケーラビリティ</br>時系列データプラットフォームに</br>必要とされる性能と可用性を担保 - ### 素早い展開</br>外部依存性を排しシンプルで使い易く</br>本当の価値をより早く得られる - ### リアルタイム</br>ホットなメトリクスデータを</br>ホットな状態でより上手く取り廻せる - ### 開発者中心</br>顧客ニーズに応じたカスタムロジックを</br>俊敏に実装、資産をコミュニティで共有 --- ## CTO Paulさんの最新の発表 [](https://speakerdeck.com/pauldix/ifql-and-the-future-of-influxdata) ## IFQLとは、もし?を問う言語? --- ## ユーザー分析関数を安価に作成したい [](https://speakerdeck.com/pauldix/ifql-and-the-future-of-influxdata?slide=123) ## その為には SQLもTICKscriptも捨てる ??? 引数が名前付き引数、TICKscriptのパイプ指定がElixir由来のパイプライン演算子、入力が暗黙の第一引数</br> IFQL</br> SQLとの互換性</br> クエリ言語の進化</br> 関数型 or SQL</br> 改善・変更が難しい</br> TICKscript</br> デバッグが難しい</br> 学習コストの問題</br> 再利用性の問題</br> 二つの言語の問題</br> 全てを再考してみる</br> 大統一言語</br> 加速度重視</br> クエリ言語とエンジンを分離</br> UI、可読性、追加への柔軟性、テスト容易性、コントリビュート性、コード共有再利用</br> Telegrafでの成功体験</br> --- class: center, middle, inverse [](https://www.influxdata.com/modern-time-series-platform/)